Thuật Toán MapReduce
Hi, các bạn! hôm nay chúng ta sẽ cùng tìm hiểu về thuật toán MapReduce trong xử lý dữ liệu lớn nhé.
Giới thiệu
Có thể bạn chưa biết ?
- Sáng lập: Các kỹ sư Google
- Một chút khái niệm: MapReduce là một mô hình lập trình và triển khai các vấn để xử lý trong Bigdata. Sử dụng thuật toán xử lý phân tán, song song trên một cụm các máy tính.
- Chương trình MapReduce bao gồm 2 phần chính :
Map procedure&Reduce. - Hệ thống MapReduce (còn gọi là Cơ sở hạ tầng MapReduce) phối hợp xử lý bằng cách sắp xếp các máy chủ phân tán, chạy song song các tác vụ khác nhau, quản lý tất cả các giao tiếp và truyền dữ liệu giữa các phần khác nhau của hệ thống và hỗ trợ đề phòng sự cố và khả năng chịu lỗi.
- Một số dự án phát triển : Apache Hadoop (open source), Apache Mahout (ASF)
Đào sâu một chút
- Chương trình MapReduce(Programming model):
input datatương ứng với keyi / valuei &output datatương ứng với keyo / valueo.- function
map (in_key, in_value) -> list(out_key, intermediate_value):- Xử lý cặp keyi / valuei.
- Đưa ra tập hợp các cặp trung gian.
- function
reduce (out_key, list(intermediate_value)) -> list(out_value):- Kết hợp tất cả các giá trị trung gian cho một key cụ thể.
- Tạo ra một tập hợp các keyo / valueo được hợp nhất (thường chỉ là một)
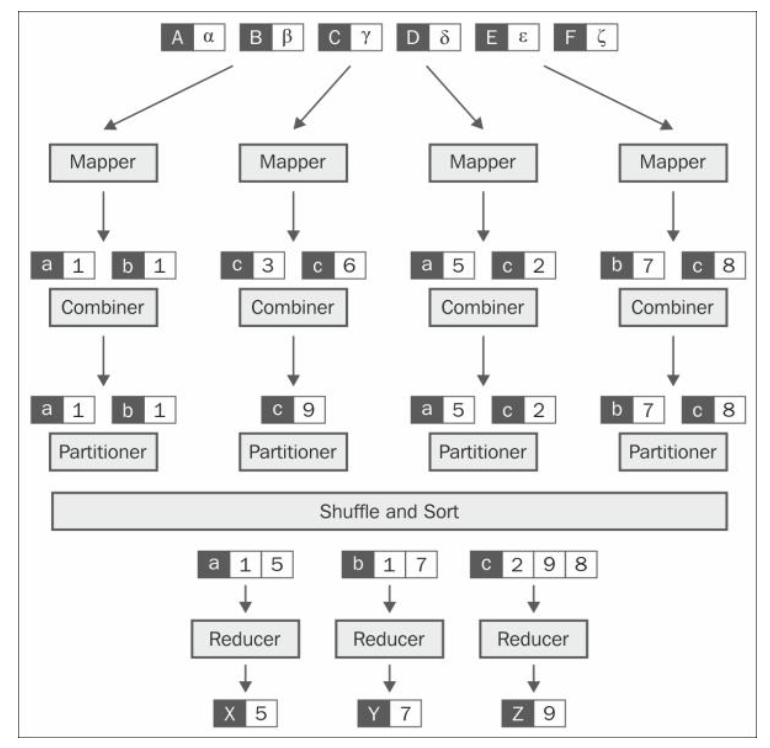
- Hệ thống MapReduce (MapReduce System):
Map: Mỗi node(máy tính) worker áp dụng hàmMap()cho dữ liệu cục bộ và ghi đầu ra vào bộ lưu trữ tạm thời. Node master đảm bảo rằng chỉ một bản sao của dữ liệu input được xử lý.Shuffle: các node worker phân phối lại dữ liệu dựa trên các key output (được tạo bởi hàmMap()), sao cho tất cả dữ liệu thuộc về một key được đặt trên cùng một node worker.Reduce: các node worker thực hiện xử lý song song từng nhóm dữ liệu output trên mỗi key.
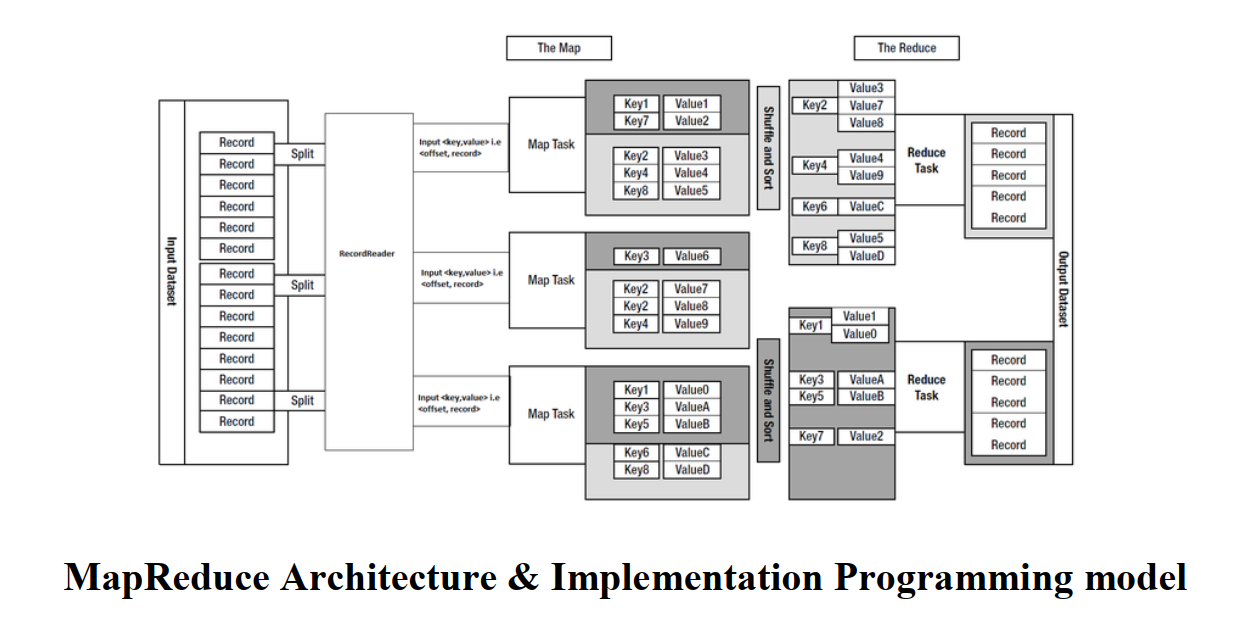
Ví dụ kinh điển
Nào chúng ta cùng đến với ví dụ kinh điển trong bài toán xử lý phân tán, song song đó là WordCount.
- Ý tưởng thực hiện :
- Chia file cần xử lý thành các phần nhỏ để xử lý.
- Xử lý các phần nhỏ được lưu phân tán độc lập trên các node và song song trên một cụm.
- Tổng hợp các kết quả thu được để đưa ra kết quả cuối cùng.
- Tổng quan :
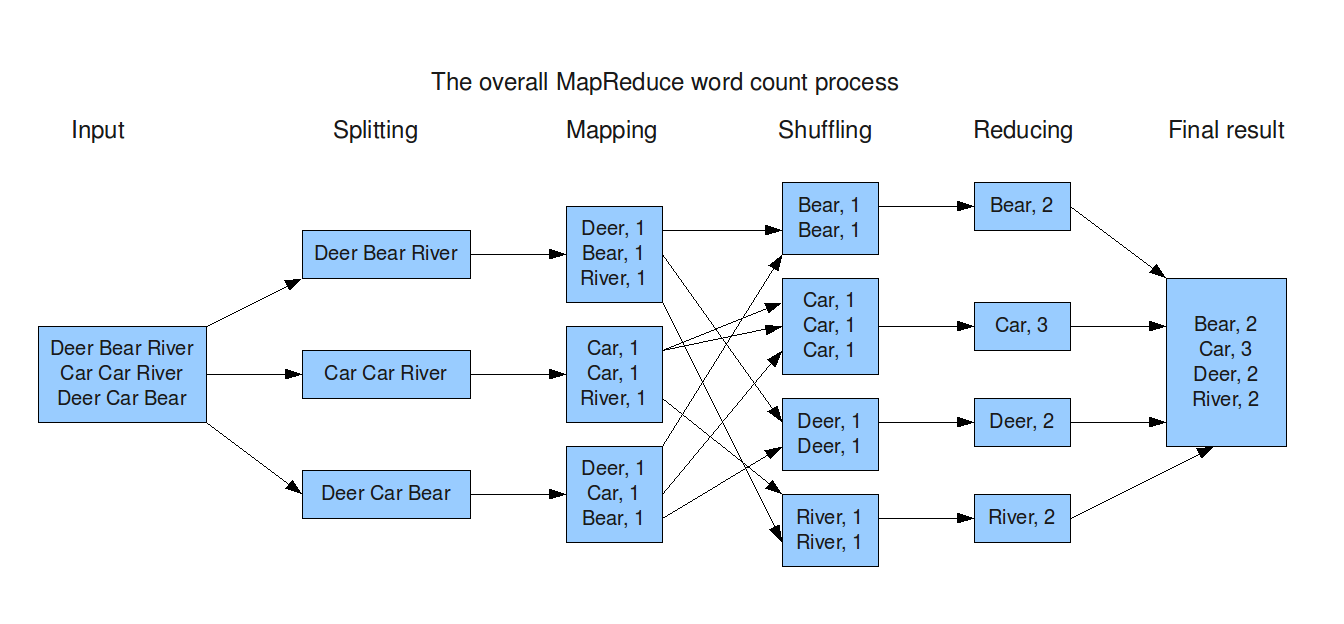
- Mã giải:
function map(String input_key, String input_value):
// input_key: document name
// input_value: document contents
for each word w in input_value:
EmitIntermediate(w, "1");
function reduce(String output_key, Iterator intermediate_values):
// output_key: a word
// output_values: a list of counts
int result = 0;
for each v in intermediate_values:
result += ParseInt(v);
Emit(AsString(result));
- Luồng xử lý:
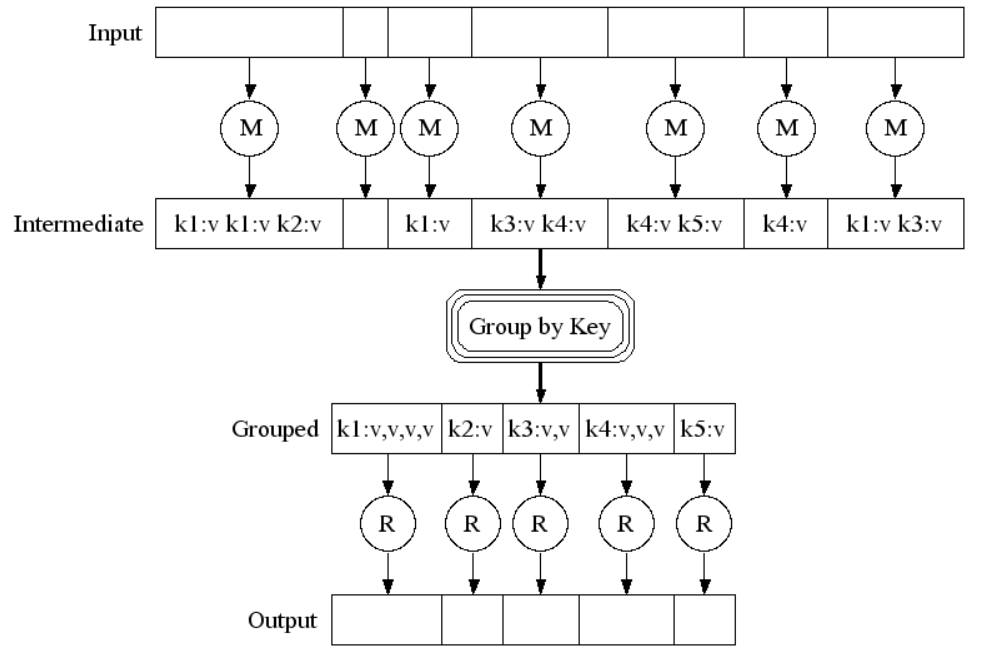
- Luồng xử lý song song:
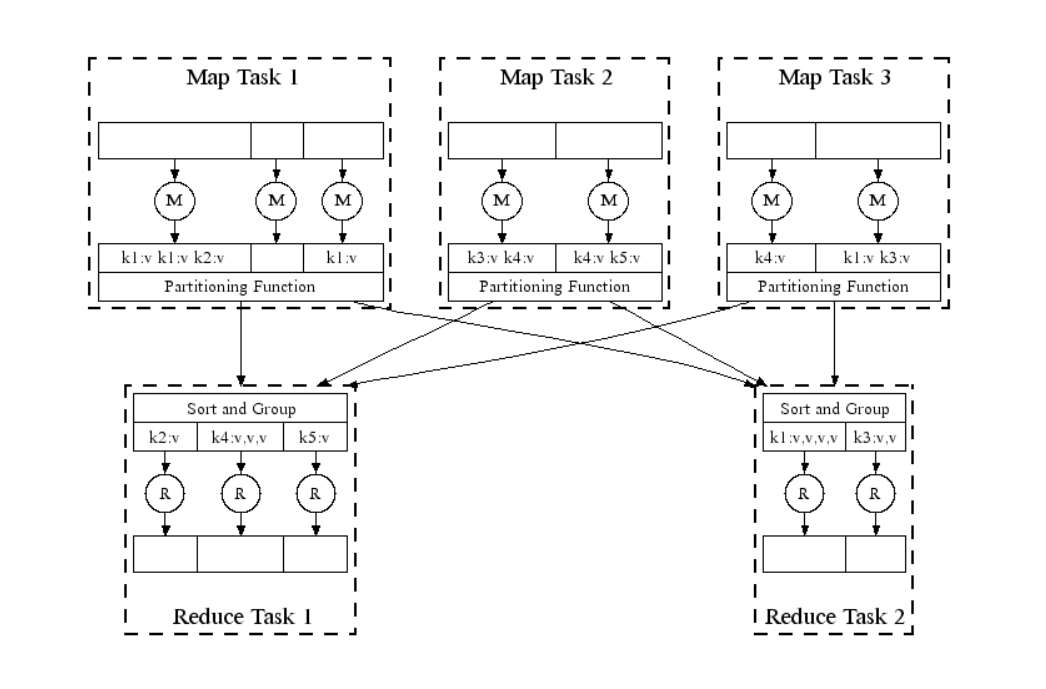
Bạn có thể tham khảo Hadoop WordCount Example